|
|
Users Guide | Patterns Reference | WebsydianExpress | Search |
|
|
Users Guide | Patterns Reference | WebsydianExpress | Search |
By far the most important addition to the list of widely used and implemented TCP/IP-based applications to come along in recent years is the World Wide Web (WWW).
A major contributor to the phenomenal success of WWW is that it is based on a communication protocol which is:
Basically, the design of WWW struck a marvelous compromise between simplicity and versatility.
There are, however, other components in WWW technology. The figure below shows the most significant elements at play when someone uses "the Web".
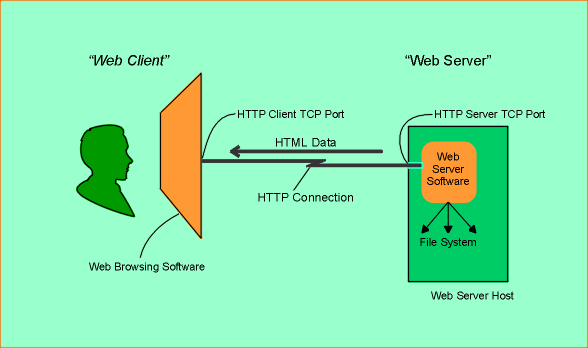
In the figure we see the following elements:
It should be noted that the figure is intended to provide a high-level overview of components that comprise web technology. Quite a few things are not represented in the figure, among which are the hardware on which the web browsing software ("the web client") executes, the operating system software of web client and web server, etc.
It is also worth noting that the term "web server" is an ambiguous term. In general, it is used to denote "the source of the data that the web browser displays", but it is usually unclear whether that means the machine or the software, or both. When the term "web server" is used in this presentation, it will refer to both the host (including operating system) and the web server software. The term "web server host" will be used to refer to the machine, and the term "web server software" will be used to refer to the software from which the "web browser data" originates.
As indicated above, the Web Server Host is used to refer to the machine used to operate the web service. A machine is generally characterized by:
In the marketplace of today, the standard hardware architecture is that of the Intel PC, which was originally defined by the IBM PC product launched in 1981. Most computers sold by far are built to this standard. A number of other hardware architectures exist; all of them more or less proprietary to a manufacturer (e.g. that of Sun SPARCstation's, IBM RISC range of midrange and workstations, or Silicon Graphics PowerServer platform) or a consortium of manufacturers (e.g. the PowerPC, defined jointly by Apple, IBM, and Motorola). The significance of hardware platform is steadily falling, as they are all increasingly built from of-the-shelf components (most important of which are, of course, the CPU component, where only a very small range of serious contenders exist).
Much more of a direct impact has the operating system (OS) used to control the hardware and its resources. For web service, the following OSs are serious contenders
and to a lesser degree desktop operating systems such as MacOS and Windows 95.
Novell, with its NetWare OS has failed to compete in this space of the market. Digital's VMS and IBM's mainframe OS MVS can provide WWW service as well, but they are not mainstream players: IBM claims that its mainframes can handle at least 3000 web transactions per second, or about 250 million hits per day. Very few organizations curently require that level of performance.
Apart from pure performance aspects we can to a large extent ignore the hardware aspects of Web Server Hosts because the OS insulates software from the hardware.
Various variants of Unix used to be by far the most common OS for web server hosts on the Internet, but Windows NT is gaining in popularity, and will likely be the most common web server OS in the very near future.
It is worth noting that more and more types of machinery provide web services (as web server host). As an example, recent network printers have built-in web server software which permit administrators to configure the printer using a web browser. We can certainly expect this trend to continue.
The Web Server Software is what implements the communications protocol that web browsers (web browsing software, strictly speaking) use to obtain web services. The protocol, as mentioned briefly above, named the Hyper Text Transfer Protocol, or HTTP for short.
Fundamentally, Web Server Software can be extremely simple. The reason, of course, is that the protocol it implements is extremely simple as well! Implementing a basic web server might be done with as little as a few hundred lines of code in an appropriate high-level programming language. The reason for this is that the only requirement for all web server software is to implement the communication protocol and emit data that it finds in its file system.
Web browsers are much harder to implement. The main reason for this is that the web browser has to interpret the data that it receives. It has to format the document, show the graphics, play the audio clips, etc., etc. To the web server software all these data formats look the same - they are just strings of bytes.
It should be pointed out, however, that today's modern web server software provide a lot more functionality than forking out data from files, including executing and managing external processes, loading and using DLLs, executing scripts in internally using built-in interpreters, interacting with complex OS services such as transaction management systems, messaging services, logging systems, directory services. etc. They are, in other words, very complex systems themselves. That, however, doesn't change the fact that the fundamental service they provide is quite simple.
The most popular web server software products are the well-known commercial offerings such as Netscape Enterprise Server, Microsoft Internet Information Server, Lotus Domino, and - perhaps surprisingly - a public domain product called Apache. Of the four main players in the web server software arena, Apache is the most widely deployed product.
We normally refer to Web Browsing Software merely as Web Browsers. Web browsers represent the Internet's face to the users. It is probably too safe to assume that anyone who has ever used the Internet has tried a Web Browser. In fact, to many people, the Internet and Web Browsers are synonymous concepts!
Technically, however, Web Browsing Software is merely any piece of software that can retrieve information from a Web Server using HTTP. All Web Browsing Software, in other words, are not graphical web browsers! The big indexing services such as Yahoo or AltaVista systematically sieve through all the information they get their hands on using web browsing software which simply retrieves all the information available from a web server to store it in a database for indexing purposes. From a web technology point of view, the software used to retrieve web documents for indexing is just another piece of web browsing software.
As web technology continues to evolve, we will see more and more kinds of web browsing software, built into personal organizers, mobile phones, cars, etc.
In today's marketplace the most popular web browsers are Microsoft's Internet Explorer and Netscape's Navigator. Both are currently available for download at no charge, at www.microsoft.com and www.netscape.com, respectively.
Unfortunately - mostly due to the fierce competition between Microsoft and Netscape - these two most popular Web Browsers do not support the exact same set of features. This goes both for the versions of HTML they support, the features in those versions of HTML, the set of scripting languages they support, the set of features in those scripting languages, the meaning of specific constructs in the scripting languages, etc. People who develop web sites and Web Applications constantly have to deal with both minor and major differences in Web Browsers.
The most common strategies in dealing with these differences are to either require all users to use the same Web Browser product, or to restrict the features used to the set that the two products (1) have in common, and (2) interpret the same way.
Fortunately it appears that there is a convergence happening in the way that new versions of Web Browsers generally include the features of the previous version of the competing Web Browser. So - over time at least - the least common denominator approach keeps improving.
HTTP is fundamentally a very simple protocol. It is a client-server protocol. That is, it is a protocol between two parties who have assigned roles. One of the parties behaves as a client (typically requesting some kind of access to some kind of resource), the other behaves as a server (providing access to the resource).
An normal HTTP interaction consists of the following steps:
HTTP v1.0 specifies several kinds of HTTP requests, the most common of which is the GET request. When we discuss Web Applications we'll discuss other kinds of HTTP requests.
A typical HTTP GET request looks something like this
GET /general/welcome.html
ACCEPT text/html, text/plain
The meaning of the request is that the HTTP client requests the data corresponding to the name /general/welcome.html. The HTTP client further indicates to the HTTP server that it is prepared to handle well-known data representations, namely those identified by the names "text/html" and "text/plain".
It is up to the web server software to interpret the value "/general/welcome.html". The interpretation maps the HTTP request to the HTTP reply. HTTP says nothing about how web servers may perform this mapping. Web server software is free to do whatever is appropriate and / or convenient.
Typically web server software (i.e. software that implements the HTTP server role) performs a very simple interpretation, namely interpreting the GET request value as a file system path name relative to some part of the file system of the web server. A server might, for example, be configured to perform this file system lookup relative to, say, C:\WEBSERVER\HTML. Under this interpretation the example HTTP GET request would cause the web server software to look for a file called
C:\WEBSERVER\HTML\GENERAL\WELCOME.HTML
Note that the interpretation in this case has two parts, (1) appending the file system directory "C:\WEBSERVER\HTML" to the HTTP GET request value, and (2) interpreting the forward slashes (/) in the request value as file system separators and mapping them to appropriate file system separators for the file system of the web server hosts OS, which - in this example - are backslashes (\).
In a simple web server software configuration, there would be two possible outcomes of this example request
Statistics show that HTTP GET requests make up at least 98% of all HTTP requests made on the Internet today. HTTP v1.0 specifies a number of other kinds of requests; these include PUT and POST which permit the HTTP client to upload data to the HTTP server under relatively unclear semantics (at least the semantics are not clearly specified by the HTTP v1.0; this lack of clear semantics is probably a major contributor to the lack of widespread use of PUT and POST HTTP requests). HTTP POST requests is one way to submit the values entered by the web browser user when submitting so-called "HTML forms".
It is important to note that the web server software is free to interpret the HTTP request in a different way. It might instead, for example, map the HTTP request to an SQL statement like
SELECT html FROM general WHERE name = "welcome"
and return the result of executing it in an appropriate context. To repeat: The meaning of the request is defined by the web server software.
Changing the interpretation of HTTP requests to something more sophisticated than retrieving a file from some part of the file system is exactly what you do when you develop Web Applications. Since web server software is generally completely generic (i.e., Microsoft and Netscape sell their web servers unchanged to many customers with widely varying requirements), what you need is to transfer the control of how specific HTTP requests are handled to software developed (or configured, or whatever) by the organization running the web service. This software then performs an interpretation appropriate for that business, and performs exactly the process required to provide an appropriate response.
How you do transfer the handling of a specific request from the generic web server software to the business-specific (or even business-critical) program and get the result back again is discussed in a separate section of this "Internet Backgrounder"; the section Web Applications. It is recommended to finish this section before continuing to the section about Web Applications.
You may have noticed in the basic operation list that the first step in an HTTP interaction is to establish a TCP connection, and the last step of the interaction is to destroy the TCP connection. There are considerable advantages and disadvantages to this short-lifetime connection property of HTTP.
The advantages of this approach are mostly related to the fact that it means that basic web server software is extremely easy to implement. Technically, the reason for the relative ease of implementing HTTP clients or servers is that the protocol means that there are very few states possible for the protocol parties (i.e. the HTTP client and server):
Moreover, the transitions that the parties go through are very simple, largely a linear progression through the states in the sequence indicated in the basic operation list. Few error conditions exist, and they are all easily dealt with. Largely, if something goes wrong, just destroy the TCP connection. This applies to both of the protocol parties - the client and the server.
The disadvantage of this short-lifetime connection property of HTTP can be illustrated by an example:
Retrieving the data needed to present a typical web page. The web browser user clicks on a link. The link corresponds to a specific GET request made to a specific web server that is listening on a specific TCP port on a host with a specific IP address. The web browser establishes a TCP connection to the specified TCP address, and makes an HTTP GET request, and subsequently receives the corresponding HTML data. This data, however, includes graphic images. These images are not embedded in the HTML data received, but are referenced using standard links.
This means that for each individual graphic image the web browser must establish a new HTTP connection! Each connection is completely independent of each other. The web server software, in other words, has no idea that each of the requests are basically part of obtaining the data required to present a single web page. Although it may infer something from the pattern of the HTTP requests it receives.
There are - at least - two important problems in this scheme
At the HTTP level each interaction is independent of any other. So if an application requires that users log in to establish their credentials with regard to the application, then this must be implemented entirely in the application logic, and information about the credentials must somehow be included in each HTTP request.
The World Wide Web Consortium (W3C) - which consists of almost all the major Internet technology players - have proposed new versions of HTTP that attempt to deal with this problem, but they have not yet been widely adopted.
These disadvantages cause major headaches for software developers trying to implement applications based on HTTP. From a developers point of view having to hand-code user session management seems an unnecessary evil. Conventional client-server technology handles this without development effort because the notion of a user session is built into the technology. Luckily, AllFusion Plex base classes allow us to deal with this problem in a highly elegant manner.
Any data can be transferred using HTTP, both text and all kinds of binary formats such as graphic images, audio, and even video. Along with an HTTP reply the web server software can supply some meta-data describing the meaning and/or representation of the reply data. We already saw in an example above that HTTP is used to retrieve all the data needed to present an entire web page; both the text (and its formatting, see below) and the graphics. There are well-established ways of describing all sorts of data representations using the HTTP meta data mechanism.
As we have seen, a web page typically consists of both (formatted) text and graphics. The text and its formatting is represented using Hyper Text Markup Language, or just HTML for short.
Fundamentally, HTML is a quite simple concept. It specifies that the content of a web page is represented using text with embedded tags. Tags are special codes with special meaning (semantics). Tags are mostly used to demarcate elements which are components of the web page, e.g. a heading, a hyper-text link, some text that is supposed to be highlighted in some way, etc. The beginning of an element is usually indicated by start tags and the end by end tags. Some elements have no content; these elements are represented by a start tag alone. Text in paragraphs is contained in <p> elements (where <p> is short for <paragraph>). Under some circumstances end tags can be omitted.
To give you an idea of HTML, here is a simple example:
<h2> This text is a heading at level one </h2>
<p> Here are some text in a paragraph.
<p> Here are some more text.
<h2> This is the text of a level two heading </h2>
<p> And some more text...
You probably get the idea. (The tags in the example have been marked red to make it easier for you to spot them.)
In a graphical Web Browser, the above text would be presented something like this:
|
As you can see, the tags control how the text is presented. The example shows simple formatting tags.
Furthermore, HTML defines how you represent hyper-text links. It might look something like this:
<p> A paragraph with a hyper-text link to the home page of
<a href="http://www.websydian.com/default.htm"> Websydian </a>
in Copenhagen. </p>
which in a graphical Web Browser would be presented something like this:
|
The HTML data above represents a paragraph element which contains a link to a web page on a web server whose Internet name is softdesign.dk. It so happens that the second line above is the HTML representation of a hyper-text link. The element is called <a> that is short for <anchor> because the target ends of hyper-text links have historically been called hyper-text link anchors. The <a> element has an "href" attribute. It is the value of this attribute that tells the web browser how to retrieve the data needed to present the web page that is to be displayed if the user wants to follow the hyper-text link.
HTML uses special tags to indicate the presence and shape of graphic images on the web page. The tags merely provide a reference the graphic images (i.e. they do not contain the graphics themselves). Typically the reference is a "href" attribute value indicating how to download the graphics data from a web server.
If you want to learn more about HTML, or you want to access an HTML reference manual, try out www.htmlhelp.com, an excellent HTML resource.
HTML has steadily evolved over time. Each time a new HTML version is agreed upon, new features are added. The first HTML versions did not specify much more than has been described above. These days HTML allows tables, interactive forms that allow the Web Browser users to enter and submit data to the web server, and much, much more. This development shows why Web Browsers are much harder to write than web server software. The web browser software is required to "understand" (i.e. correctly interpret, present, and otherwise handle) HTML and other data formats. The web server does not have such requirements with respect to the contents of the data it is serving. It just delivers data along with the meta-data properties describing it.
The most radical parts of recent HTML specifications require the web browser to be able to correctly execute Java code (used in this context the Java code constitutes a Java Applet) and little scripts associated with specific elements in the HTML data in so-called Dynamic HTML.
Web Browsing Software (Web Browsers) typically presents its (human) user with a document, represented in HTML, in which hypertext links may be embedded. When the users selects a link to follow, the Web Browser is supposed to display the document to which the link points. However, to display the document, the Web Browser must typically contact a Web Server and request the data representing the document to be displayed.
This begs the following question:
How does the Web Browser know how and where to contact the Web Server, and what to request once contact has been made?
The answer is URLs, or Universal Resource Locators, a compact representation of the address of a resource available on the Internet, typically a document.
We have actually already encountered a URL in this section: It was embedded in the link anchor in one of the HTML examples. It looked like this:
http://www.websydian.com/websydiannet/app
The general format of a URL is something like this
<scheme>://<host>[:portnum]/<resource>?<params>
The http://www.websydian.com/websydiannet/app example above did not include any parameters.
<scheme> refers to the method the Web Browser should use to retrieve the resource. By far the most common scheme is http, which indicates that the Web Browser should use the HTTP protocol. Another, less common scheme is ftp (File Transfer Protocol), a classic Internet protocol; although it seems to be on the way to be replaced by HTTP; at least for "consumer" data transfers.
<host> is the Internet name of the host where the resource can be retrieved, <resource> is the name of the resource that should be given when requesting the resource, and <params> is an optional set of parameters for the request.
So how does the Web Browser know how to get the service? By connectring to the host identified by <host> (on the TCP port number <portnum> if specfied, otherwise port number 80), using the protocol scheme <scheme> to ask for the resource given as <resource>.
Proceed with next section Understanding Web Applications.